
¿Qué es el Web Scraping?
El web scraping, también conocido como raspado de datos o contenidos, consiste en un conjunto de técnicas utilizadas para extraer datos de la web de manera automatizada. Específicamente, esta recopilación de información se realiza mediante un software especializado que permite indexar sitios web de forma rutinaria. Como resultado, esta práctica se ha convertido en una herramienta esencial para diversos sectores, desde el marketing digital hasta la investigación académica. Por ejemplo, existen servicios que comparan los precios de productos vendidos en línea. Estos servicios obtienen la información mediante scrapers que leen los datos de los sitios web y comparan los precios publicados.
¿Qué se puede “scrapear” legalmente?
Esta herramienta permite scrapear todo tipo de datos disponibles en la web; sin embargo, puede que exista la posibilidad de que se necesite el uso de herramientas adicionales a las que el web scraping brinda, dependiendo del sitio web del que se pretenda obtener información. Un caso muy común en el que el web scraping necesita de una herramienta adicional es cuando se pretende obtener información de algún contenido visual. Caso contrario, el web scraping puede operar utilizando interfaces de programación de las aplicaciones de un sitio web. No obstante, no se debe confundir la publicidad de un dato con la habilitación para su tratamiento. El hecho de que un dato personal sea público (accesible a través de internet e indexable) tiene escasa relevancia, a efectos de determinar si su tratamiento es legítimo o no. Para llevar a cabo cualquier tratamiento de datos personales, será necesario basarse en una de las legitimaciones consagradas en Ley N° 29733, “Ley de Protección de Datos Personales”, y su respectivo Reglamento aprobado por el Decreto Supremo N° 003-2013-JUS.0
¿Existe el Web Scraping Malicioso?
El web scraping malintencionado se refiere a la recolección de datos de un sitio web sin el consentimiento o la intención del editor de compartirlos. Este tipo de scraping puede involucrar datos personales o propiedad intelectual, pero también puede aplicarse a cualquier información que no esté destinada a ser pública. Esta definición presenta ciertas áreas grises, ya que aunque muchos datos personales están protegidos por leyes, no todos los datos cuentan con esa protección. Sin embargo, esto no implica que no existan situaciones en las que el scraping de dichos datos pueda ser ilegal o infringir los términos de servicios en ciertos casos.
Si bien el web scraping puede ofrecer grandes beneficios para la sociedad, como la transparencia comercial y la investigación académica, también puede ser contraproducente y ocasionar daños en la seguridad cibernética. Los estafadores pueden utilizar la información recopilada para cometer fraude cibernético. Por lo tanto, es crucial realizar el web scraping de manera ética y legal, garantizando el respeto a la privacidad y los derechos tanto de los individuos como de las entidades propietarias de los datos.
¿Qué lenguajes de programación se utilizan para el Web Scraping?
Python destaca como el lenguaje más popular para web scraping debido a su accesibilidad y a la disponibilidad de bibliotecas especializadas como Scrapy, Selenium y Beautiful Soup, simplificando la extracción y gestión de datos. Por otro lado, JavaScript, reconocido principalmente por su uso en el desarrollo web del lado del cliente, también se emplea en el scraping, especialmente con herramientas como Puppeteer, que permite el control de navegadores para la obtención de datos. Además, PHP, ampliamente utilizado en el desarrollo web, cuenta con bibliotecas como PHP Simple HTML DOM Parser, que facilitan el scraping de contenido HTML.
¿Cuál es el proceso básico del Web Scraping?
Como ya se ha mencionado, para realizar el web scraping existen distintos lenguajes de programación mediante la cual se recolectarán la data de los sitios web; sin embargo, a grandes rasgos, los pasos a seguir se encuentran simplificado en el gráfico a continuación.
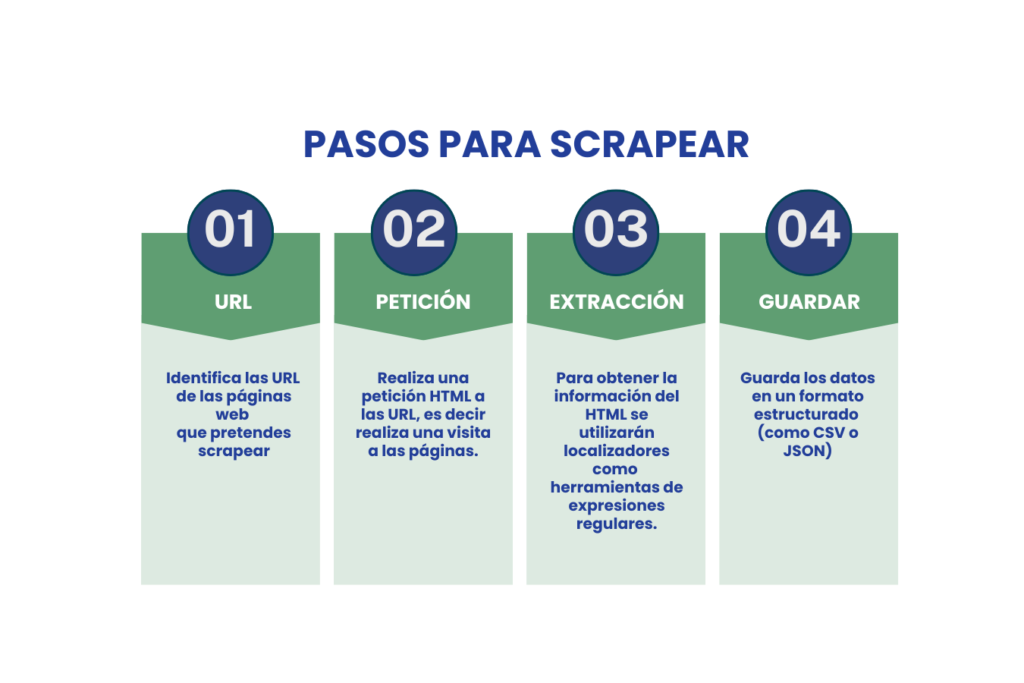
Es crucial destacar que el proceso de web scraping no siempre es sencillo, especialmente cuando se trata de recopilar datos a gran escala. Uno de los mayores desafíos radica en mantener actualizado el scraper conforme los sitios web modifican sus datos o implementan políticas anti-scraping.
Ventajas del Web Scraping
Una de las principales ventajas del web scraping, es la velocidad con la que la información puede ser recopilada; la extracción de datos que de forma manual tomaría un período de tiempo bastante largo, con el web scraping se lograría en tiempos más reducidos. De esta manera, se busca economizar los gastos en los que se incurre cuando se opera de manera tradicional.
De otro lado, el web scraping incrementa la precisión de los datos extraídos, pues al eliminar la forma tradicional de recopilar la información, se deja de lado el error humano.
La rentabilidad del procedimiento es otra de las ventajas que nos ofrece el scraping, ello debido a que se encuentran disponibles en el mercado, a precios realmente razonables.
Finalmente, los datos que se obtienen del web scraping son datos estructurados y limpios, toda vez que luego de que los datos son recopilados, generalmente sigue la etapa que incluye limpiar y reorganizar. En ese sentido, los motores de búsqueda hacen que el compendio de datos obtenido, siendo convertidos en datos estructurados.
¿Se puede prevenir el scrapping?
Existen diversas medidas técnicas para prevenir el scraping en plataformas y páginas web, adaptadas específicamente a cada sitio. Estas incluyen la implementación de Captchas durante el inicio de sesión y la aplicación de sesiones con tiempo limitado, lo cual reduce notablemente la efectividad del scraping. Otros métodos eficaces son las restricciones de acceso que requieren verificación de información de contacto, como números de teléfono mediante SMS o llamadas para completar el registro. También se pueden emplear enlaces diseñados para ser detectados únicamente por bots, lo que ayuda a limitar el acceso no autorizado.
Además, es posible restringir el acceso a cuentas de usuario específicas mediante la detección de patrones de navegación sospechosos, como movimientos rápidos o predecibles que indican actividad automatizada. También se pueden implementar desafíos técnicos como solicitudes de JavaScript o el uso de cookies para identificar y limitar el acceso de usuarios no humanos, acciones que son ejecutadas automáticamente por la mayoría de los navegadores estándar.
En conclusión, el web scraping, fundamentalmente utilizado para extraer datos de manera automatizada de la web, ofrece beneficios significativos en áreas como el marketing y la investigación. Sin embargo, su uso debe ser ético y legalmente responsable, respetando siempre los términos de servicio y la privacidad de los datos. Es esencial implementar medidas técnicas adecuadas, como Captchas y restricciones de acceso, para prevenir el scraping no autorizado. Estas acciones no solo protegen la integridad de los sitios web, sino que también aseguran el uso ético de la información en beneficio de la sociedad y las empresas.
Esperamos que esta información sea útil para usted y su empresa. Si requiere asesoramiento legal sobre este tema, no dude en ponerse en contacto con nosotros.